
Deep Learning Reference Stack v5.0 Now Available
17 Dec, 2019
Artificial Intelligence (AI) continues to be deployed across a growing number of use cases: healthcare and financial services, to wildfire detection [1], image-to-image translation/recognition, and other high-demand workloads. AI has the power to impact almost every aspect of our daily lives, and Intel is committed to advancing the Deep Learning (DL) workloads that power AI.
Intel understands how complex it is to create and deploy applications for deep learning workloads. That’s why we developed an integrated Deep Learning Reference Stack, optimized for Intel® Xeon® Scalable processor and released the companion Data Analytics Reference Stack, as well as a Database Reference Stack.
Today, we’re pleased to announce the Deep Learning Reference Stack 5.0 release, incorporating customer feedback and delivering an enhanced user experience with support for expanded use cases. This release incorporates enhancements of Natural Language Processing (NLP), which helps computers process and analyze large amounts of natural language data, among other features.
With this update, Intel further enables developers to quickly prototype and deploy DL workloads, reducing complexity while maintaining the ability to customize solutions. Among the features in this release:
- TensorFlow* 1.15 and TensorFlow* 2.0, an end-to-end open source platform for machine learning (ML).
- PyTorch* 1.3, an open source machine learning framework that accelerates the path from research prototyping to production deployment.
- PyTorch Lightning*, a lightweight wrapper for PyTorch designed to help researchers set up all the boilerplate state-of-the-art training.
- Transformers*, a state-of-the-art Natural Language Processing (NLP) for TensorFlow 2.0 and PyTorch.
- Intel® OpenVINO™ model server version 2019_R3, delivering improved neural network performance on Intel processors, helping unlock cost-effective, real-time vision applications.
- Intel Deep Learning Boost (DL Boost) with AVX-512 Vector Neural Network Instruction (Intel AVX-512 VNNI) designed to accelerate deep neural network-based algorithms.
- Deep Learning Compilers (TVM* 0.6), an end-to-end compiler stack.
Benefits of the Deep Learning Reference Stack
With this release, Intel focused on incorporating Natural Language Processing (NLP) in the Deep Learning Reference Stack to demonstrate that pretrained language models can be used to achieve state-of-the-art results [2]. NLP can be used for Natural language inference, machine translation, and for higher layers of transfer learning.
Kubeflow Pipelines*, a platform for building and deploying portable, scalable, machine learning (ML) workflows, are used for deployment of deep learning containerized images. This enables and simplifies orchestration of machine learning pipelines, making it easy for developers to use numerous use cases and applications on the Deep Learning Reference Stack.
We incorporated Transformers, a state-of-the-art general-purpose architecture for Natural Language Understanding (NLU) and Natural Language Generation (NLG). This helps to seamlessly move from pre-trained or fine-tuned models to productization.
For the PyTorch-based Deep Learning Reference Stack, we incorporated Flair, a powerful NLP library that allows developers to apply natural language processing (NLP) models to text, such as named entity recognition (NER), part-of-speech tagging (PoS), sense disambiguation, and classification.
In addition to the Docker deployment model, we integrated the Deep Learning Reference Stack with popular Function-as-a-Service technologies, which help deploy event-driven, independent functions and microservices dynamically managed and scaled based on machine resources.
Additionally, we provided simple and easy to use end-to-end use cases for the Deep Learning Reference Stack to help developers quickly prototype and bring up the stack in their environments. Some examples:
- Pix-to-Pix: Demonstrates use of the performant Deep Learning Reference Stack for image-to-image translation within a serverless infrastructure. This solves challenges of synthesizing photos from abstract designs, reconstructing objects from edge maps, and colorizing images, among other tasks.
- GitHub* Issue Classification: Allows developers to use the Deep Learning Reference Stack to analyze the issue content and tag it automatically, saving time for developers and directing their focus on solving other complex issues.
We’ll unveil additional use cases targeting developer and service provider needs in the coming weeks.

This release also incorporates the latest versions of popular developer tools and frameworks:
- Operating System: Clear Linux* OS, customized to individual development needs and optimized for Intel platforms, including specific use cases like Deep Learning.*
- Orchestration: Kubernetes to manage and orchestrate containerized applications for multi-node clusters with Intel platform awareness.
- Containers: Docker Containers and Kata Containers with Intel® VT Technology for enhanced protection.
- Libraries: Intel® Math Kernel Library for Deep Neural Networks (MKL DNN), highly-optimized for mathematical function performance.
- Runtimes: Python application and service execution support.
- Deployment: As mentioned earlier, Kubeflow Seldon*, and Kubeflow Pipelines* are used for the deployment of the Deep Learning Reference Stack.
- User Experience: Jupyter Hub*, a multi-user Hub that spawns, manages, and proxies multiple instances of the single-user Jupyter notebook server.
Each layer of the Deep Learning Reference Stack has been performance-tuned for Intel architecture, enabling impressive performance compared to non-optimized stacks.
Performance gains for the Deep Learning Reference Stack with Intel® OpenVINO™ and ResNet50 as follows:
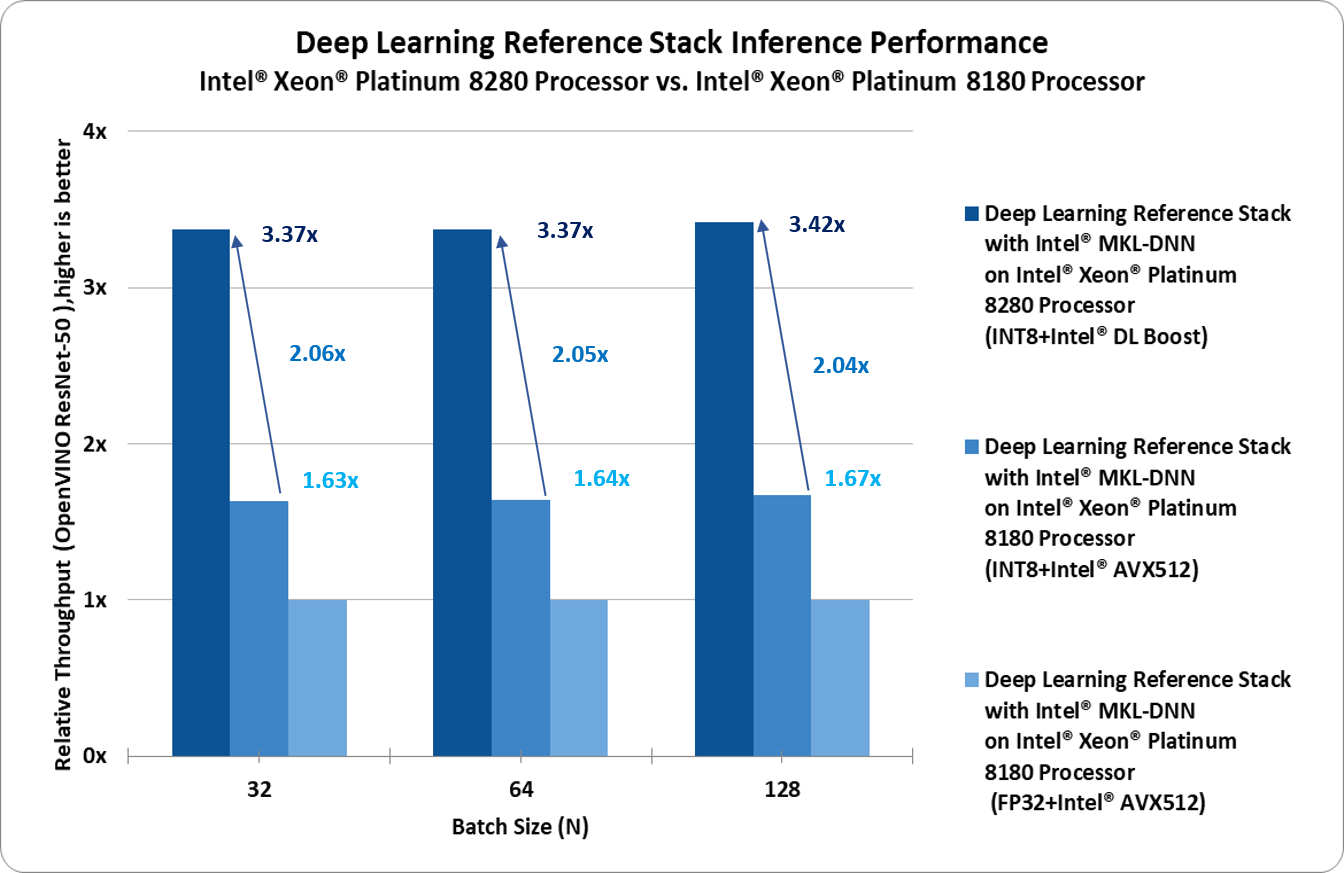
Second Generation Intel® Xeon® Scalable Platform –2 socket Intel® Xeon® Platinum 8280 Processor (2.7GHz, 28 cores), HT On, Turbo ON, Total Memory 384 GB (12 slots/ 32GB/ 2933 MHz), BIOS: SE5C620.86B.02.01.0008.031920191559 (ucode:0x500002c), Clear Linux 31690, Kernel 5.3.11-869.native, Deep Learning ToolKit: OpenVINO™ 2019_R3, AIXPRT V1.0 benchmark(https://www.principledtechnologies.com/benchmarkxprt/aixprt/), Workload:ResNet-50, Compiler: gcc v9.2.1, Intel® MKL DNN v0.18, 56 inference instances/2 sockets, Datatype: INT8
Intel® Xeon® Scalable Platform –2 socket Intel® Xeon® Platinum 8180 Processor(2.5GHz, 28 cores), HT On,Turbo ON, Total Memory 384 GB (12 slots/ 32GB/ 2666 MHz), BIOS: SE5C620.86B.02.01.0008.031920191559 (ucode:0x2000065), Clear Linux 31690, Kernel 5.3.11-869.native, Deep Learning ToolKit: OpenVINO™ 2019_R3, AIXPRT V1.0 benchmark(https://www.principledtechnologies.com/benchmarkxprt/aixprt/), Workload:ResNet-50, Compiler: gcc v9.2.1, Intel® MKL DNN v0.18, 56 inference instances/2 sockets, Datatype: INT8, FP32
Intel will continue working to help ensure popular frameworks and topologies run best on Intel architecture, giving customers a choice in the right solution for their needs. We are using this stack to innovate on our current Intel® Xeon® Scalable processors and plan to continue performance optimizations for coming generations.
Visit the Clear Linux* Stacks page to learn more and download the Deep Learning Reference Stack code, and contribute feedback. As always, we welcome ideas for further enhancements through the stacks mailing list.
[1] https://www.cnn.com/2019/12/05/tech/ai-wildfires/index.html
[2] https://ruder.io/nlp-imagenet/
Notices and Disclaimers
Software and workloads used in performance tests may have been optimized for performance only on Intel microprocessors.
Performance tests, such as SYSmark and MobileMark, are measured using specific computer systems, components, software, operations and functions. Any change to any of those factors may cause the results to vary. You should consult other information and performance tests to assist you in fully evaluating your contemplated purchases, including the performance of that product when combined with other products. For more complete information, visit www.intel.com/benchmarks.
Performance results are based on testing as of 11/29/2019 and may not reflect all publicly available security updates. No product or component can be absolutely secure.
System configuration
Second Generation Intel® Xeon® Scalable Platform –2 socket Intel® Xeon® Platinum 8280 Processor (2.7GHz, 28 cores), HT On, Turbo ON, Total Memory 384 GB (12 slots/ 32GB/ 2933 MHz), BIOS: SE5C620.86B.02.01.0008.031920191559 (ucode:0x500002c), Clear Linux 31690, Kernel 5.3.11-869.native, Deep Learning ToolKit: OpenVINO™ 2019_R3, AIXPRT V1.0 benchmark(https://www.principledtechnologies.com/benchmarkxprt/aixprt/), Workload:ResNet-50, Compiler: gcc v9.2.1, Intel® MKL DNN v0.18, 56 inference instances/2 sockets, Datatype: INT8
Intel® Xeon® Scalable Platform –2 socket Intel® Xeon® Platinum 8180 Processor(2.5GHz, 28 cores), HT On,Turbo ON, Total Memory 384 GB (12 slots/ 32GB/ 2666 MHz), BIOS: SE5C620.86B.02.01.0008.031920191559 (ucode:0x2000065), Clear Linux 31690, Kernel 5.3.11-869.native, Deep Learning ToolKit: OpenVINO™ 2019_R3,AIXPRT V1.0 benchmark(https://www.principledtechnologies.com/benchmarkxprt/aixprt/), Workload:ResNet-50, Compiler: gcc v9.2.1, Intel® MKL DNN v0.18, 56 inference instances/2 sockets, Datatype: INT8, FP32
Optimization Notice: Intel’s compilers may or may not optimize to the same degree for non-Intel microprocessors for optimizations that are not unique to Intel microprocessors. These optimizations include SSE2, SSE3, and SSSE3 instruction sets and other optimizations. Intel does not guarantee the availability, functionality, or effectiveness of any optimization on microprocessors not manufactured by Intel. Microprocessor-dependent optimizations in this product are intended for use with Intel microprocessors. Certain optimizations not specific to Intel microarchitecture are reserved for Intel microprocessors. Please refer to the applicable product User and Reference Guides for more information regarding the specific instruction sets covered by this notice.
Notice Revision #20110804
Intel, the Intel logo, and Intel Xeon® are trademarks of Intel Corporation or its subsidiaries in the U.S. and/or other countries. *Other names and brands may be claimed as the property of others.
© Intel Corporation