Performant Containerized Go* Applications with Intel® Advanced Vector Extensions 512 on Clear Linux* OS
26 May, 2020
Performant Containerized Go* Applications with Intel® Advanced Vector Extensions 512 on Clear Linux* OS
Author: Jing Wang
Intel Corporation
Major cloud software such as Docker*, etcd*, Istio*, Kubernetes*, Prometheus*, and Terraform* use the Go* programming language for core cloud infrastructure components. Why are they using Go? Compared with many other scripting languages, Go is fast!
This article shows how to develop performant Go applications that leverage Intel® Advanced Vector Extensions 512 (Intel® AVX-512) and a Go container based on Clear Linux* OS to improve the performance potential of Go.
Background
Intel AVX-512 is a set of SIMD instructions that can accelerate performance for workloads with large and precise datasets. With Intel AVX-512, applications can pack 32 double-precision and 64 single-precision floating point operations within the 512-bit vectors, as well as eight 64-bit and sixteen 32-bit integers.
Intel® Deep Learning Boost (Intel® DL Boost) is a set of technologies introduced with 2nd generation Intel® Xeon® processors to accelerate CPU performance in AI applications. It includes Intel® DL Boost Vector Neural Network Instructions (VNNI) which extends Intel AVX-512 features by introducing four new instructions for accelerating inner convolutional neural network loops.
Go is an open source programming language with concurrency mechanisms that help developers make full use of multicore and networked machines. It is expressive, modular, and efficient. Go based data science and analytic applications typically leverage gonum, a set of libraries for matrices, statistics, and optimization. Libraries like gonum build on top of a lower-level BLAS (Basic Linear Algebra Subroutines) layer.
Gonum / netlib creates wrapper packages that provide an interface to Netlib CBLAS implementations. Because netlib uses C and CBLAS, using gonum/netlib provides indirect use of an Intel processor’s Intel AVX-512 capability, if available on the running system. The gonum/netlib recommended BLAS layer for performance on Linux is OpenBLAS.
OpenBLAS is an optimized open source BLAS library based on GotoBLAS2 1.13 BSD version, implemented in C. It provides a BLAS layer implementation with Intel AVX-512 acceleration that is adaptable to Intel® Advanced Vector Extensions 2 (Intel® AVX2) or Intel® Streaming SIMD Extensions (Intel® SSE) only platforms.
OpenBLAS uses OpenMP* as the mechanism for parallelism. The OpenMP API provides support for parallel programming with shared-memory processors across multiple platforms. It provides a threading layer with configurable environment variables to balance maximum performance and resource scheduling.
Clear Linux OS is optimized for performance. It uses the latest compiler optimized for Intel® architecture with the latest features and compiler flags to optimize builds. The Clear Linux OS uses a multiple library build approach and will link the library most optimized for the capabilities of the processor in the running system. Clear Linux OS provides optimized software components across the software stack that support Go development, such as Intel AVX-512 optimized glibc and OpenBLAS.
Go container based on Clear Linux OS
A Go container based on Clear Linux OS (clearlinux/golang) was published to make the performance optimizations in Clear Linux OS easy to use with Go. The container includes OpenBLAS and OpenMP.
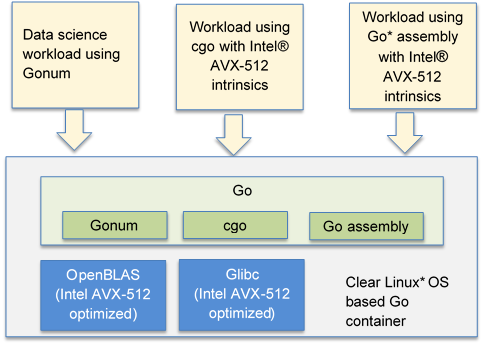
Figure 1 clearlinux/golang container components
The clearlinux/golang container is easy to use and customize. To use the container, pull the clearlinux/golang image from DockerHub* and run it:
docker pull clearlinux/golang
To build your own Go container based on the clearlinux/golang image:
- Define a Dockerfile:
FROM clearlinux/golang:latest RUN swupd bundle-add openblas ADD /app $GOPATH/src WORKDIR $GOPATH/src/app - Build the new container from the Dockerfile:
docker build -f dockerfile
Tuning performance
OpenBLAS and OpenMP expose configuration variables that influence performance of shared-memory multiprocessing applications. The clearlinux/golang container is based on Clear Linux OS which uses compiler options that are optimized for Intel architecture. Clear Linux OS patches the default values for the OpenBLAS and OpenMP configuration variables as follows:
- USE_OPENMP: Specifies that OpenBLAS should use OpenMP. The default value is USE_OPENMP=1.
- OMP_NUM_THREADS: Specifies the number of OpenMP threads to use in parallel regions. The value should be from one to the maximum number of physical CPU cores. The default value is OMP_NUM_THREADS=[number of physical CPU cores of the platform].
- OMP_DYNAMIC: Specifies whether to enable or disable the dynamic adjustment of the number of threads within a team. The default value is OMP_DYNAMIC=disabled.
- OMP_THREAD_LIMIT: Specifies the maximum number of OpenMP threads to use in a contention group. The default value is OMP_THREAD_LIMIT=undefined.
These configuration values can be overridden as needed by passing arguments to Docker or Kubernetes.
Intel AVX-512 with Go
The Go programming language can use a system’s Intel AVX-512 capabilities via three methods:
- Direct access with Go assembly
- Access with the Go cgo interface using intrinsics for Intel AVX-512
- Indirect access with 3rd party libraries such as Gonum
The method you choose will depend on your application and language preferences.
If you are already familiar with low-level programming using assembly or C, or your application will use data-intensive computing, the Go assembly or cgo methods will result in more performance improvement. This is because both Go assembly and cgo operate directly on the Intel AVX-512 instructions and registers.
If you are familiar with the Go language and do not want to worry about low-level programming, your application can still take advantage of Intel AVX-512 using the Gonum method with the netlib interface.
The examples below show implementations of each method with tests to evaluate performance. Hardware and software configurations used in the examples and tests are described in Table 1 and Table 2.
|
Hardware |
|
|---|---|
|
Platform |
Intel® Xeon® Platinum 8269CY CPU @ 2.50 GHz (Intel processor code-named Cascade Lake) in Aliyun* Cloud |
|
CPU |
1 |
|
Threads/Cores |
16/8 |
|
Memory |
16G |
|
Disk |
200G SSD |
|
Software |
|
|---|---|
|
Clear Linux OS |
Version 32310 |
|
Linux Kernel |
5.3.14 x86_64 |
|
GCC |
9.2.1 |
|
OpenBLAS |
0.3.7 |
|
Go |
1.13 |
|
Gonum |
0.6.2 |
|
Runc (container runtime) |
1.0.0-rc9 |
Intel AVX-512 with Go assembly
Go has invented its own assembly language based on the Plan 9 assembler. The Go assembler exposes AVX registers directly to developers. If you aren’t familiar with Go assembly, look at A Primer on Go Assembly.
This example implements vector dot multiplication in Go assembly and takes advantage of Go Intel AVX-512 support. The example is tested in the clearlinux/golang container. The workflow and stack for the example is shown in Figure 2.
For this example:
- Instructions like VINSERTI128 and VPSHUFD are the SIMD instructions.
- MMX registers are M0...M7.
- SSE registers are X0...X15.
- AVX registers are Y0...Y15.
- AVX-512 registers are Z0…Z15 (introduced in Go release 1.11).
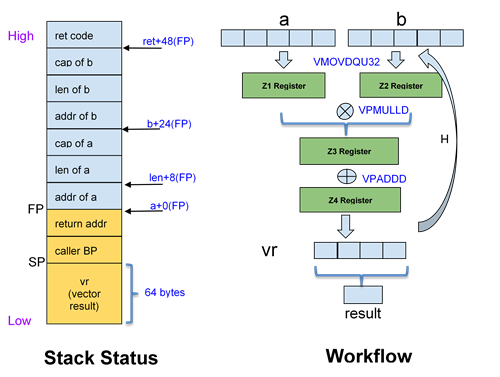
Figure 2 Stack view and workflow of sample matrix dot vector program
- Declare an empty Go function VDotProdAVX512 and VDotProdAVX2 respectively with two int32 vectors, a[] and b[], as parameters. The function should return an int32 result which will be the vector dot production of [a] and [b].
func VDotProdAVX512(a[] int32, b[] int32) int32 func VDotProdAVX2(a[] int32, b[] int32) int32 - Write the implementation of the DotProdAVX512 function in Go assembly.
// definition of func VDotProdAVX512(a[] int32, b[] int32) int32 // $96 denotes the size in bytes of the stack-frame. // $56 specifies the size of the arguments passed in by the caller. TEXT ·VDotProdAVX512(SB), $96-56 // Move the address of a, address of b, and array length to registers // SI, DI, and CX respectively. For simplicity, we assume the length of // array a and b are equal and addresses have a 64-byte alignment. MOVQ a+0(FP), SI // address of a MOVQ b+24(FP), DI // address of b MOVQ len+8(FP), CX // array length // Z4 is an accumulator that sums all vector multiplication results. // Compute Z3 = Z1 * Z2 and Z4 = Z4 + Z3 using the VMOVDQU32, VPMULLD // and VPADDD instructions. If the array length is greater than 16, // loop execution until we reach the end of array. Store Z4 to the stack // frame address, vr, which is 64 bytes (512 bits) long VPXORD Z4, Z4, Z4 start: VMOVDQU32 (SI), Z1 VMOVDQU32 (DI), Z2 VPMULLD Z1, Z2, Z3 VPADDD Z3, Z4, Z4 ADDQ $64, SI ADDQ $64, DI SUBQ $16, CX JNZ start VMOVDQU32 Z4, d0-64(SP)// vector result to stack // Convert the vector result to a scalar result by summing // the INT32 elements and return the result. LEAQ d0-64(SP), BX MOVQ BX, 0(SP) MOVQ $16, AX // array length MOVQ AX, 8(SP) CALL ·Sum32(SB) // invoke Sum32 to get scalar value MOVL 24(SP), AX MOVL AX, ret+48(FP) // final result RET TEXT ·Sum32(SB), $0-32 MOVQ $0, SI MOVQ av+0(FP), BX // address of vector MOVQ lv+8(FP), CX // len of vector start: ADDL (BX), SI ADDQ $4, BX DECQ CX JNZ start MOVL SI, ret+24(FP) RET - Write the implementation of the DotProdAVX2 function in Go assembly for comparison.
// definition of func VDotProdAVX2(a[] int32, b[] int32) int32 TEXT ·VDotProdAVX2(SB), $64-56 MOVQ a+0(FP), SI // address of a MOVQ b+24(FP), DI // address of b MOVQ len+8(FP), CX // array length VPXORD Y4, Y4, Y4 start: VMOVDQU32 (SI), Y1 VMOVDQU32 (DI), Y2 VPMULLD Y1, Y2, Y3 VPADDD Y3, Y4, Y4 ADDQ $32, SI ADDQ $32, DI SUBQ $8, CX JNZ start VMOVDQU32 Y4, d0-32(SP) LEAQ d0-32(SP), BX MOVQ BX, 0(SP) MOVQ $8, AX //array length MOVQ AX, 8(SP) CALL ·Sum32(SB) MOVL 24(SP), AX MOVL AX, ret+48(FP) RET - Create a benchmark using Go's Package testing functionality. The test performs vector dot multiplication using Go assembly with Intel AVX-512. For comparison, the same test is implemented using Go assembly with Intel AVX2 and Go without AVX. Each test measures execution time (ns/op) and data throughput (Mb/s) of the function.
import "testing" func BenchmarkVDotProdAVX512(b *testing.B) { var d1[1024] int32 var d2[1024] int32 for i := 0; i < 1024; i++ { d1[i] = int32(i + 1); d2[i] = int32(2 * i); } var sum2 int32 = 0 b.SetBytes(1024) b.ResetTimer() for i := 0; i < b.N; i++ { sum2 += VDotProdAVX512(d1[:], d2[:]) % 1024 } } func BenchmarkVDotProdAVX2(b *testing.B) { var d1[1024] int32 var d2[1024] int32 for i := 0; i < 1024; i++ { d1[i] = int32(i + 1); d2[i] = int32(2 * i); } var sum2 int32 = 0 b.SetBytes(1024) b.ResetTimer() for i := 0; i < b.N; i++ { sum2 += VDotProdAVX2(d1[:], d2[:]) % 1024 } } func VDotProd(a[] int32, b[] int32) int32 { var sum1 int32 sum1 = 0 for i := 0; i < len(a); i++ { sum1 += a[i] * b[i] } return sum1 } func BenchmarkVDotProd(b *testing.B) { var d1[1024] int32 var d2[1024] int32 for i := 0; i < 1024; i++ { d1[i] = int32(i + 1); d2[i] = int32(2 * i); } var sum2 int32 = 0 b.SetBytes(1024) b.ResetTimer() for i := 0; i < b.N; i++ { sum2 += VDotProd(d1[:], d2[:]) % 1024 } } - Run the Go benchmarks.
See Table 1 and Table 2 for configuration details. For more complete information about performance and benchmark results, visit www.intel.com/benchmarks.$ go test -bench . goos: linux goarch: amd64 pkg: golang_assembly BenchmarkVDotProd-8 1817728 659 ns/op 1553.48 MB/s BenchmarkVDotProdAVX2-8 11320402 106 ns/op 9632.04 MB/s BenchmarkVDotProdAVX512-8 15705526 76.4 ns/op 13404.84 MB/s
The test results show that the implementation using Go assembly with Intel AVX-512 (BenchmarkVDotProdAVX512-8) had a shorter execution time and higher data throughput than the implementations using Go assembly with Intel AVX2 (BenchmarkDotProdAVX2-8) and Go without AVX (BenchmarkDotProd-8).
Intel AVX-512 with Go cgo
Cgo enables Go packages to call C code. Cgo outputs Go and C files that can be combined into a single Go package.
The example below implements vector dot multiplication with VNNI, part of Intel AVX-512, using cgo. It is tested in the clearlinux/golang container.
Figure 3 provides an overview of how Intel AVX-512 VNNI works.
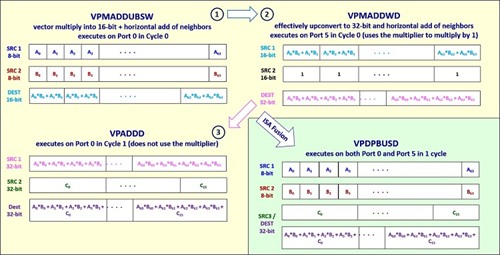
Figure 3 Intel AVX-512 VNNI overview
- In the preamble section of the Go program, define CFLAGS, LDFLAGS, and include header files.
package avx512 /* #cgo CFLAGS: -mavx512f -mavx512vl -mavx512bw -mavx512vnni #cgo LDFLAGS: -lm #include <stdio.h> #include <math.h> #include <stdlib.h> #include <x86intrin.h> - Create a VNNI dot multiplication function using Intel AVX-512 in C code.
For code simplicity we assume the int8 input vectors (x, y) have a 64-byte alignment. _mm512_dpbusds_epi32 is the key fused multiply-add (FMA) instruction, which uses one instruction to implement vector dot multiplication from an int8 input to an int32 output. Without using the FMA instruction, three separate instructions are needed to execute the multiplication, as shown in Figure 3.int32_t avx512_dot_vnni(const size_t n, int8_t *x, int8_t *y) { static const size_t single_size = 64; const size_t end = n / single_size; __m512i *vx = (__m512i *)x; __m512i *vy = (__m512i *)y; __m512i vsum = {0}; __m512i *psum = &vsum; for(size_t i = 0; i < end; ++i) { *psum = _mm512_dpbusds_epi32(vsum, vx[i], vy[i]); } int32_t *t = (int32_t *)psum; int32_t sum = 0; for (int i = 0; i < 16; i++) { sum += t[i]; } return sum; } - Implement a dot multiplication function using Intel AVX2 for comparison.
int32_t avx2_dot_int8(const size_t n, int8_t *x, int8_t *y) { static const size_t single_size = 32; const size_t end = n / single_size; const int16_t op4[16] = {[0 ... 15] = 1}; __m256i *vx = (__m256i *)x; __m256i *vy = (__m256i *)y; __m256i vsum = {0}; int32_t *t = (int32_t *)&vsum; for(size_t i = 0; i < end; ++i) { __m256i vresult1 = _mm256_maddubs_epi16(vx[i], vy[i]); __m256i vresult2 = _mm256_madd_epi16(vresult1, *(__m256i *)&op4); // trick here is to stop compiler over-optimize *(__m256i *)t = _mm256_add_epi32(vsum, vresult2); } int32_t sum = 0; for (int i = 0; i < 8; i++) { sum += t[i]; } return sum; } */ - Define a simple Go function that calls the C function from the previous step.
import "C" import ( "math" "reflect" "unsafe" ) func Dot_avx512_vnni(size int, x, y []int8) int32 { size = align(size) dot := C.avx512_dot_vnni((C.size_t)(size), (*C.int8_t)(&x[0]), (*C.int8_t)(&y[0])) return int32(dot) } func Dot_avx2_int8(size int, x, y []int8) int32 { size = align(size) dot := C.avx2_dot_int8((C.size_t)(size), (*C.int8_t)(&x[0]), (*C.int8_t)(&y[0])) return int32(dot) } - Create a benchmark using Go’s Package testing functionality. The test performs vector dot multiplication using Go cgo with Intel AVX-512 VNNI. For comparison, the same test is implemented using Go cgo with Intel AVX2. Each test measures execution time (ns/op) and data throughput (Mb/s) of the function.
import "testing" func BenchmarkAVX512DotVnni(b *testing.B) { size := benchsize vx := Make_int8(size) vy := Make_int8(size) for i := 0; i < size; i++ { vx[i] = int8(rand.Intn(127)) vy[i] = int8(rand.Intn(127)) } b.SetBytes(int64(size)) b.ResetTimer() var result int32 = 0 for i := 0; i < b.N; i++ { result += Dot_avx512_vnni(size, vx, vy) vx[i % size] = int8(result) vy[i % size] = int8(result) } } func BenchmarkAvx2DotInt8(b *testing.B) { size := benchsize vx := Make_int8(size) vy := Make_int8(size) for i := 0; i < size; i++ { vx[i] = int8(rand.Intn(127)) vy[i] = int8(rand.Intn(127)) } b.SetBytes(int64(size)) b.ResetTimer() var result int32 = 0 for i := 0; i < b.N; i++ { result += Dot_avx2_int8(size, vx, vy) vx[i % size] = int8(result) vy[i % size] = int8(result) } } - Run the Go benchmark.
See Table 1 and Table 2 for configuration details. For more complete information about performance and benchmark results, visit www.intel.com/benchmarks.$ go test -bench . -benchtime 10s goos: linux goarch: amd64 pkg: golang-avx BenchmarkAvx2DotInt8-8 99550977 122 ns/op 8491.32 MB/s BenchmarkAVX512DotVnni-8 100000000 106 ns/op 9760.42 MB/s
The test results show that the implementation using Go cgo with Intel AVX-512 VNNI (BenchmarkAVX512DotVnni-8) had the shortest execution time and higher data throughput compared to the implementation using Go cgo with Intel AVX2 and the implementation using Go cgo with Intel AVX-512.
Intel AVX-512 with Gonum
Gonum netlib is a set of wrapper packages that provide an interface to Netlib CBLAS implementations such as OpenBLAS. This example implements matrix multiplication using Gonum netlib with an OpenBLAS backend. It is tested in the clearlinux/gonum container.
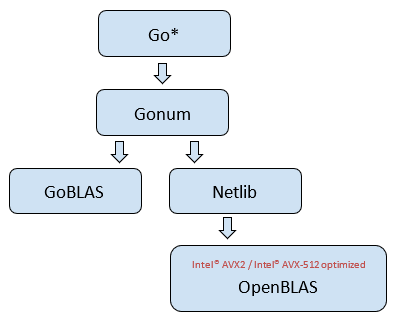
Figure 4 Diagram of Gonum system architecture
- Install the Gonum core packages and netlib packages which provide the interface to the CBLAS implementations.
go get -u gonum.org/v1/gonum/... go get -d gonum.org/v1/netlib/...Or pull the available clearlinux/gonum docker container from DockerHub which contains all needed packages.
docker pull clearlinux/gonum - Import the required packages into your Go program. To use netlib CBLAS, you must explicitly import gonum.org/v1/netlib/blas/netlib at the beginning of the file.
package main import ( "testing" "math/rand" "gonum.org/v1/gonum/mat" "gonum.org/v1/gonum/blas/gonum" "gonum.org/v1/netlib/blas/netlib" "gonum.org/v1/gonum/blas" "gonum.org/v1/gonum/blas/blas64" ) - Create a benchmark using Go's Package testing functionality. The test performs matrix multiplication using the General Matrix Multiply (GEMM) implementation of Gonum netlib CBLAS, which calls the OpenBLAS implementation underneath.
In the sample code below, blas64.Use(netlib.Implementation{}) causes netlib CBLAS to be used instead of the Go BLAS.
The test measures execution time (ns/op) and data throughput (Mb/s) of the function.func BenchmarkCBlas64(b *testing.B) { blas64.Use(netlib.Implementation{}) in1 := make([]float64, M * K) in2 := make([]float64, K * N) for i := range in1 { in1[i] = rand.NormFloat64() in2[i] = rand.NormFloat64() } out := make([]float64, M * N) b.SetBytes(M*K*N) b.ResetTimer() for i := 0; i < b.N; i++ { blas64.Gemm(blas.NoTrans, blas.NoTrans, 1, blas64.General{ Rows: M, Cols: K, Stride: K, Data: in1, }, blas64.General{ Rows: K, Cols: N, Stride: N, Data: in2, }, 1, blas64.General{ Rows: M, Cols: N, Stride: N, Data: out, }) } } -
For comparison, create a second benchmark that performs the same matrix multiplication using the default Go BLAS implementation with same test code.
func BenchmarkGoBlas64(b *testing.B) { blas64.Use(gonum.Implementation{}) // copy the rest of the code from the BenchmarkCBlas64 function above // … } -
Run the Go benchmarks.
$ go test -bench . -benchtime 5s goos: linux goarch: amd64 BenchmarkGoBlas64-8 2209 2708501 ns/op 9968.61 MB/s BenchmarkCBlas64-8 12014 496631 ns/op 54366.31 MB/sSee Table 1 and Table 2 for configuration details. For more complete information about performance and benchmark results, visit www.intel.com/benchmarks.
The test results show that the Gonum netlib CBLAS (BenchmarkCBlas64-8) implementation had a shorter execution time and higher data throughput than the default GoBLAS (BenchmarkGoBlas64-8) implementation.
Conclusion
The examples show how to use Intel AVX-512 with Go to improve application performance using three different methods: direct access with Go assembly, using the Go cgo interface with intrinsics for Intel AVX-512, and via indirect access with 3rd party libraries such as Gonum.
Each method showed that using Intel AVX-512 improved Go application performance, with shorter execution times and improved date throughput overall. Using Go assembly with direct access to the CPU instruction set was faster than indirect access using cgo or Gonum.
Clear Linus OS makes it easy to use Intel AVX-512 in Go because Clear Linux OS provides a deeply optimized software stack, including Intel AVX-512 enabled software.
By providing ready-to-use configurable Clear Linux OS based containers for Go applications, this performance potential can be easily deployed to a Kubernetes cluster. Both containers are available on DockerHub:
Check out these container images and let us know if you see a difference in your Go development using Intel AVX-512 with Clear Linux OS!
Notices & Disclaimers
Software and workloads used in performance tests may have been optimized for performance only on Intel microprocessors.
Performance tests, such as SYSmark and MobileMark, are measured using specific computer systems, components, software, operations and functions. Any change to any of those factors may cause the results to vary. You should consult other information and performance tests to assist you in fully evaluating your contemplated purchases, including the performance of that product when combined with other products. For more complete information visit www.intel.com/benchmarks.
Performance results are based on testing as of 2020/01/10 and may not reflect all publicly available updates. See Table 1 and Table 2 above for configuration details. No product or component can be absolutely secure. Your costs and results may vary.
Intel technologies may require enabled hardware, software or service activation.
© Intel Corporation. Intel, the Intel logo, and other Intel marks are trademarks of Intel Corporation or its subsidiaries. Other names and brands may be claimed as the property of others.
See backup for configuration details. For more complete information about performance and benchmark results, visit www.intel.com/benchmarks.
Intel does not control or audit third-party data. You should consult other sources to evaluate accuracy.
Intel's compilers may or may not optimize to the same degree for non-Intel microprocessors for optimizations that are not unique to Intel microprocessors. These optimizations include SSE2, SSE3, and SSSE3 instruction sets and other optimizations. Intel does not guarantee the availability, functionality, or effectiveness of any optimization on microprocessors not manufactured by Intel. Microprocessor-dependent optimizations in this product are intended for use with Intel microprocessors. Certain optimizations not specific to Intel microarchitecture are reserved for Intel microprocessors. Please refer to the applicable product User and Reference Guides for more information regarding the specific instruction sets covered by this notice.
Refer to http://software.intel.com/en-us/articles/optimization-notice for more information regarding performance and optimization choices in Intel software products.