
Improving Python* NumPy Performance on Kubernetes* using Clear Linux* OS
04 Mar, 2020
Improving Python* NumPy Performance on Kubernetes* using Clear Linux* OS
Authors: Long Wang, Rick Y Wang, and Ken Lu
Introduction
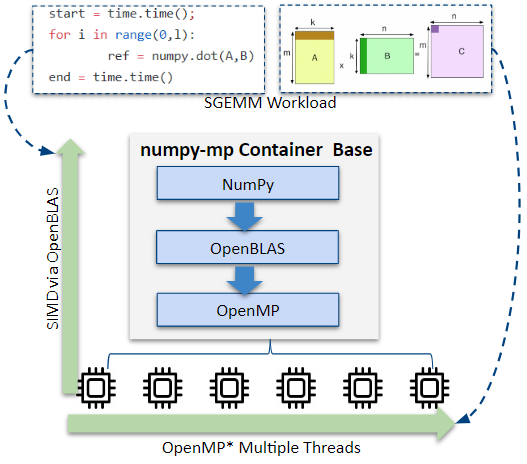
This article shows how Python NumPy performance can be improved on Kubernetes using a Clear Linux* OS-based Docker* container with an adaptive configuration strategy. The container image, clearlinux/numpy-mp, provides an adaptive configuration strategy for Kubernetes or traditional High Performance Computing (HPC) scenarios using Intel® Advanced Vector Extensions 512 (Intel® AVX-512) optimized OpenBLAS and OpenMP*.
The numpy-mp dockerfile is available on GitHub* and the clearlinux/numpy-mp Docker image is published on DockerHub*.
Background
Python has emerged as one of the top programming languages for data science and machine learning. Python's low learning curve, the inclusion of data science libraries such as NumPy, SciPy, and Pandas, and its flexibility in problem-solving make it more ideally suited for data science applications
NumPy is Python's vectorization solution and the foundational library of the Python data science stack, as shown in Figure 1. Vectorization of matrices transforms the data in a matrix from multiple columns into a single column format. This allows a single operation to be applied to a list (the column), instead of multiple operations applied to multiple items (multiple columns). This simplification is fundamental to solving many data science problems because it enables parallelism and minimizes the number of operations required to compute answers.
NumPy performance for vectorization workloads can be optimized by making use of SIMD processor instructions, such as Intel AVX-512 or Intel® Advanced Vector Extensions 2 (Intel® AVX2). These CPU instructions help performance in the Basic Linear Algebra Subprograms (BLAS) layer and the parallel threading layer libraries commonly used in HPC solutions such as OpenMP, Intel® Threading Building Blocks (Intel® TBB), and Numba workqueue. The optimizations from both the BLAS and parallel threading layers are important to the final result.
Container technology is widely used in both HPC and Kubernetes ecosystems, however the HPC workload scheduling is very different compared to the pod-based Kubernetes scheduling. For example, HPC applications leverage a multiple processing layer like OpenMP to maximize parallel computing within a cluster. In contrast, Kubernetes schedules resources within a cluster based on CPU metrics via CPU quota and cpuset.
Even though the containerized NumPy stack came from the HPC world, it is also used with Kubernetes for use cases such as image processing, machine learning, and deep learning. Due to how Kubernetes manages resource scheduling, additional overhead can be introduced, restricting NumPy throughput.
Experiments
To identify where NumPy performance could be improved on Kubernetes, single-precision floating General Matrix Multiply (SGEMM) dot product performance was measured. Experiments were run on the official Clear Linux OS Docker container image using the OpenBLAS NumPy SGEMM script to test throughput of SGEMM, a common operation used in machine learning. Figure 2 shows the general configuration of the experiments. The hardware and software configurations used in the experiments are described in Table 1 and Table 2.
|
Hardware |
|
|---|---|
|
Platform |
Dell Precision 5820 Tower X-Series |
|
Number of sockets |
1** |
|
CPU |
Intel® Core™ i9-9900X CPU @ 3.50GHz |
|
Number of Cores |
10 (20 threads) |
|
Hyperthreading (HT) |
On |
|
Intel® Turbo Boost |
On |
|
BIOS version |
1.9.2 |
| Ucode | 0x2000065 |
|
System DDR memory configuration: slots / cap / run-speed |
4 slots / 64 GB / 2666 MHz / DDR4 DIMM |
|
Network interface controller (NIC) |
Ethernet Connection (5) I219-LM |
|
Platform controller hub (PCH) |
Intel® Z370 chipset |
** Note: This paper focuses on a single socket use case. The multiple socket use case is more complex and would need to consider additional application-level optimizations.
|
Software Versions |
|
|---|---|
|
Clear Linux OS |
31700 |
|
Linux Kernel |
5.3.12-871.native |
|
Mitigation variants (1,2,3,3a,4, L1TF) |
Full mitigation |
|
Python* |
3.7.4 |
|
NumPy |
1.17.2 |
|
OpenBLAS |
0.3.7 |
|
GOMP (OpenMP) |
9.2.0 |
|
Docker* |
19.03.2 |
|
Kubernetes* |
1.16.3 |
In Clear Linux OS, the default NumPy stack is built on the following open source components:
- OpenBLAS: An optimized open source BLAS library based on GotoBLAS2 1.13 BSD version. It provides a BLAS layer implementation with Intel AVX-512 acceleration that is adaptable to Intel AVX2 or Intel® Streaming SIMD Extensions (Intel® SSE) only platforms. The Clear Linux OS multiple library build approach automatically uses the library most optimized for the capabilities of the running processor.
Alternatively, the Intel® Math Kernel Library can be configured as a BLAS backend. - OpenMP: An API that supports multi-platform shared memory multiprocessing programming in C, C++, and Fortran. It provides a threading layer with configurable environment variables such as OMP_NUM_THREADS, OMP_DYNAMIC, and OMP_THREAD_LIMIT that provide orchestration to balance maximum performance and resource scheduling.
Experiment 1: Results with different numbers of threads
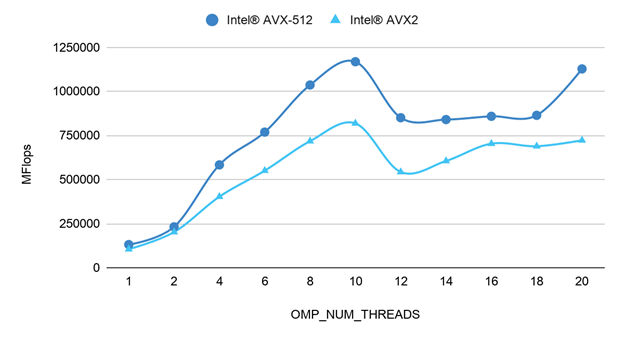
The OpenMP OMP_NUM_THREADS variable specifies the number of threads to use in parallel regions. To observe the impact of OpenMP thread count on performance on a fixed matrix, the SGEMM benchmark was run in the container with the OMP_NUM_THREADS variable set to a range of values from 1 to 20. Both Intel AVX2 and Intel AVX-512 were tested to determine if the impact of OMP_NUM_THREADS was observable on different instruction sets.
Figure 3 shows the SGEMM dot product results with matrix size 1280 (M=K=N) for different thread numbers. It shows that OMP_NUM_THREADS influences SGEMM performance. The SGEMM benchmark reached maximum performance when OMP_NUM_THREADS = 10.
The impact of OMP_NUM_THREADS on performance was similar on both the Intel AVX2 and Intel AVX-512.
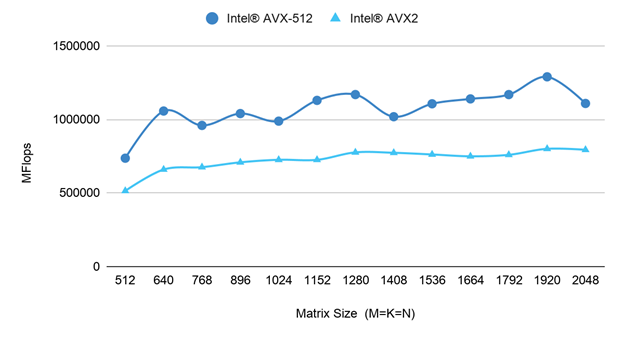
Experiment 2: Results with different matrix sizes
Experiment 2 builds on the results of experiment one. The number of OMP_NUM_THREADS was set to 10 and the SGEMM benchmark was run for different matrix sizes (M=K=N) ranging from 512 to 2048. Both Intel AVX2 and Intel AVX-512 were tested to determine if the impact of matrix size was observable on different instruction sets.
Figure 4 shows the SGEMM dot product performance with OMP_NUM_THREADS=10 for different matrix sizes. It shows that with a fixed OMP_NUM_THREADS setting, the SGEMM performance across different matrix sizes is relatively stable. The impact of matrix size on performance was similar on both the Intel AVX2 and Intel AVX-512.
Experiment 1 and 2 show that OMP_NUM_THREADS and matrix size have a similar impact on performance for both Intel AVX-512 and Intel AVX2. For simplicity, the newer Intel AVX-512 was selected as the basis for subsequent experiments.
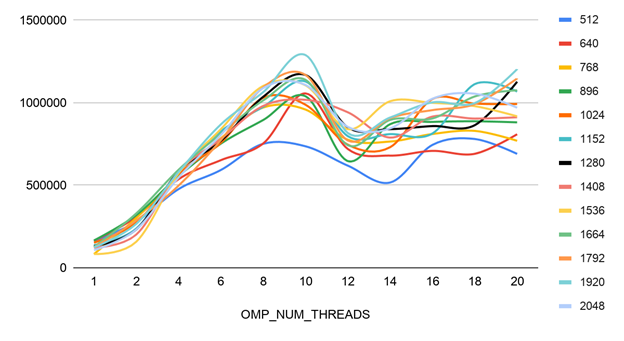
Experiment 3: Results with different matrix sizes and numbers of threads
Experiment 3 shows how the number set for OMP_NUM_THREADS impacts performance for different matrix sizes (M=K=N). Using the Intel AVX-512 container, OMP_NUM_THREADS was set to values ranging from 1 to 20 and the SGEMM benchmark was run for matrices ranging from 512 to 2048.
Figure 5 shows the SGEMM dot product performance with Intel AVX-512 for various thread counts and matrix sizes. The chart shows that the benchmark reached maximum performance for most matrix sizes when OMP_NUM_THREADS = 10.
Experiment 4: Comparison of different CPU resource management strategies in Kubernetes
For CPU-bound workloads like SGEMM, the performance is impacted by both the number of SIMD/threads and by the type of infrastructure it is deployed on.
CPUs are referred to as compute resources in Kubernetes. Compute resources are measurable quantities that can be requested, allocated, and consumed. There are multiple CPU management policies and quality of service policies, including the default policy with Completely Fair Scheduler (CFS) quota, a static policy with BestEffort, Burstable, and Guaranteed QoS. Each of these policies depends on CPU quota, managed by cgroupfs within the Linux kernel CPU subsystem.
In experiment 4, two strategies were tested on a matrix size 1280 (M=K=N) across a range of limits:
Strategy A: Set OMP_NUM_THREADS=10 statically in the Kubernetes service, based on the outcome of experiment 3.
Strategy B: Set OMP_NUM_THREADS equal to the limits of CPU quota specified by the Kubernetes service configuration. The following example shows an excerpt from the Kubernetes service YAML file implementing Strategy B with a value of 5:
spec:
containers:
- name: numpy-mp
image: clearlinux/numpy-mp
resources:
limits:
cpu: “5”
env:
- name: OMP_NUM_THREADS
value: “5”
Figure 6 compares the results of running the SGEMM benchmark with both strategies. The chart shows that Kubernetes limits=10 is the inflection point. It is notable that 10 is the number of physical cores on the CPU of the test system. When the CPU resources requested by the container are less than the number of physical cores of the CPU (left of limits=10 in Figure 6) Strategy B was more performant. When the CPU resources requested by the container are greater than the number of physical cores of the CPU (right of limits=10 in Figure 6) Strategy A was more performant. Interestingly, neither approach achieved the best performance across all Kubernetes limits settings.
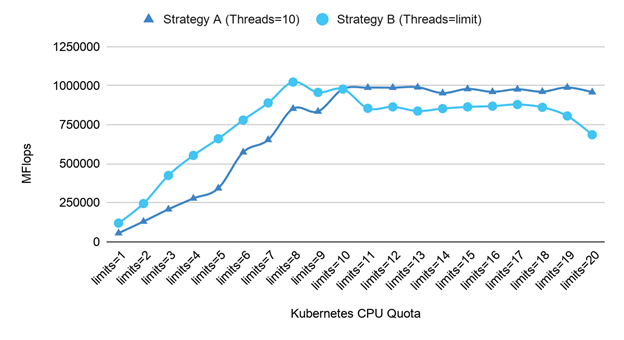
Analysis and Tuning
OpenBLAS calculates OMP_NUM_THREADS according to the Linux sysconf() function in a traditional way. It is not aware of Kubernetes CPU quota configurations.
Using limits=5 as an example of a CPU limit less than the number of physical cores on the system, the CPU resource available to the NumPy pod is limited by Kubernetes to 5. With limits=5:
- OpenBLAS sets the number of threads to 10 in Strategy A, as shown in Figure 6. All threads run on a total of 10 cores, but only get half time slices each due to the Kubernetes quota limit. To limit CPU resources of the pod to 5, Kubernetes will throttle the container and artificially restrict the CPU, which introduces additional overhead.
- OpenBLAS sets the thread number to 5 in Strategy B, as shown in Figure 6. These 5 threads run on 5 cores with full-time slices. Kubernetes does not intercept CPU throttling. Consequently, there is no additional overhead.
Using limits=15 as an example of a CPU limit greater than the number of physical cores on the system, the CPU resources available to NumPy is limited by Kubernetes to 15. With limits=15:
- OpenBLAS still sets the number of threads to 10 in Strategy A. All threads run on a total of 10 cores and get full-time slices. There is no additional overhead.
- OpenBLAS sets the number of threads to 15 in Strategy B. These 15 threads run on 15 cores (only 10 physical cores) with multithreading. There is additional overhead due to overscheduling.
For CPU-bound workloads, one thread can consume the full computing capability of one physical core. Multiple concurrent threads running on the same physical core will contend for the CPU resources and introduce additional overhead.
Solution
Based on these findings, an adaptive approach was developed that computes the number of OpenMP threads to use in order to minimize CPU overhead, with consideration to the assigned compute resource in Kubernetes. The number of threads is determined based on a number of CPU attributes including Kubernetes CPU quota, number of physical cores, the affinities, and topology of the cores.
The adaptive approach implements a simple algorithm:
- When round-up(assigned compute resource) <= number of physical cores
- set OMP_NUM_THREADS=round-up(assigned compute resource)
- set OMP_NUM_THREADS=round-up(assigned compute resource)
- When round-up(assigned compute resource) > number of physical cores
- set OMP_NUM_THREADS=number of physical cores
Figure 7 compares the results of running the SGEMM benchmark with the adaptive strategy, compared to the other static strategies. The adaptive strategy provided a solution that achieves an optimized solution across all the tested Kubernetes CPU quota scenarios.
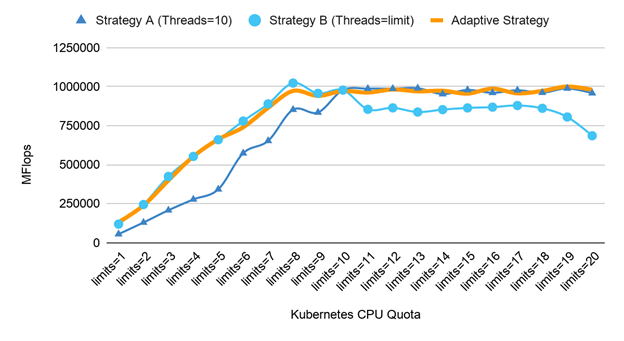
The adaptive approach is an ideal solution for multithreaded workloads on a single socket CPU with multiple cores and is applicable for both Docker and Kubernetes containers. For a system with multiple sockets and Non-Uniform Memory Access (NUMA), it’s recommended to split the workload into parallel processes and run concurrently on each NUMA-node using the described adaptive strategy.
Other strategies for resource management that may positively impact performance are not covered in this article. For example, an alternate strategy could divide the input matrix into appropriately sized “chunks” before processing across multiple threads. More advanced customers could consider developing their own CPU resource management strategy.
numpy-mp container
To make this adaptive strategy easy to use, the clearlinux/numpy-mp container image was created and published. It is based on Clear Linux OS and includes Python, NumPy, OpenBLAS, and OpenMP.
Note: The numpy-mp container is built on open source components from Clear Linux OS, but does not use the proprietary Python library intel-numpy.The optimizations and configurations of the OpenMP threads setting for Kubernetes are also suitable for other BLAS/MP libraries.
The numpy-mp container provides several configuration variables. Normally these configuration values are not easily accessed inside a container or are set statically at build-time. In the numpy-mp container image, these configuration values are exposed so they can be set by the operator. The configuration variables are:
- OMP_NUM_THREADS
Specifies the default number of threads to use in parallel regions.
If undefined, an optimized value will be set by the adaptive strategy script set-num-threads.sh. This script is called by docker-entrypoint.sh at container start.
Alternatively, the user may explicitly set its value in either the Docker run command or in the Kubernetes yaml file, according to the application scenario. For example, if the developer splits the workload from the application layer into multiple processes, the OpenMP threads can be set to 1.
- OMP_THREAD_LIMIT
Specifies the number of threads to use for the whole program. If undefined, the number of threads is not limited.
- OMP_DYNAMIC
Enable or disable the dynamic adjustment of the number of threads within a team. If undefined, dynamic adjustment is disabled by default.
- OMP_SCHEDULE
Specifies schedule type and chunk size. If undefined, dynamic scheduling and a chunk size of 1 is used.
- OMP_NESTED
Enable or disable nested parallel regions, such as whether team members can create new teams. If undefined, nested parallel regions are disabled by default.
Summary
This article analyzes NumPy workload performance on Kubernetes. Factors were identified that impact performance including Kubernetes CPU quota, the number of CPU cores, and active Python parallelization numbers for threads and processes.
The clearlinux/numpy-mp container was created with Intel AVX-512 optimized Clear Linux OS content to package the adaptive strategy and make it easy to use.
An adaptive OpenMP multithreading strategy for Kubernetes was developed that provides configuration points to address the identified factors impacting performance. This solution reduces CPU active cores and achieves improved performance on a Kubernetes cluster when tested with the OpenBLAS built-in benchmark for NumPy SGEMM.
Notices & Disclaimers
Software and workloads used in performance tests may have been optimized for performance only on Intel microprocessors. Performance tests, such as SYSmark and MobileMark, are measured using specific computer systems, components, software, operations and functions. Any change to any of those factors may cause the results to vary. You should consult other information and performance tests to assist you in fully evaluating your contemplated purchases, including the performance of that product when combined with other products. For more complete information visit www.intel.com/benchmarks.
Performance results are based on testing as of 2019/11/21 and may not reflect all publicly available security updates. See backup for configuration details. No product or component can be absolutely secure.
Your costs and results may vary.
Intel technologies may require enabled hardware, software or service activation.
© Intel Corporation. Intel, the Intel logo, and other Intel marks are trademarks of Intel Corporation or its subsidiaries. Other names and brands may be claimed as the property of others.
See backup for configuration details. For more complete information about performance and benchmark results, visit www.intel.com/benchmarks
Intel does not control or audit third-party data. You should consult other sources to evaluate accuracy.
Intel's compilers may or may not optimize to the same degree for non-Intel microprocessors for optimizations that are not unique to Intel microprocessors. These optimizations include SSE2, SSE3, and SSSE3 instruction sets and other optimizations. Intel does not guarantee the availability, functionality, or effectiveness of any optimization on microprocessors not manufactured by Intel. Microprocessor-dependent optimizations in this product are intended for use with Intel microprocessors. Certain optimizations not specific to Intel microarchitecture are reserved for Intel microprocessors. Please refer to the applicable product User and Reference Guides for more information regarding the specific instruction sets covered by this notice. Notice Revision #20110804